



Recap From Day 059
Day 059, we looked at working with time; Hidden Markov Models(HMMs). We learned that HMMs can also give us information about which state we’re likely to be in at the current time. For instance, if we assume that we’re drawing a gesture at a point in time, what state of the sequence are we most likely to be in? That is, how far through the gesture are we? So, those are HMMs in a nutshell.
Today, we’ll look at tradeoffs of classifiers other than kNN
Working with time
Tradeoffs of classifiers other than kNN
We have seen previously how classifiers other than kNN can sometimes learn to generalize more effectively by creating explicit models that are tuned from the training data. There are likely to make decisions boundaries that are smoother and to create classifiers that perform more accurately on unseen data.
](https://cdn-images-1.medium.com/max/2000/1*GuVt0UAJHp2h7lWiHbr-FA.png)
On the other hand, we’ve also seen that when the assumptions of the model are not appropriate to the learning problem, or when the parameters of the learning algorithm are not set in an appropriate way, these models can fail.
If dynamic time-warping is like a nearest-neighbour classifier using only the distance measurement without any underlying model, then Hidden Markovs Models are more like these other classifiers. HMMs can perform very well when the model of the data is appropriate and they can perform very poorly otherwise.
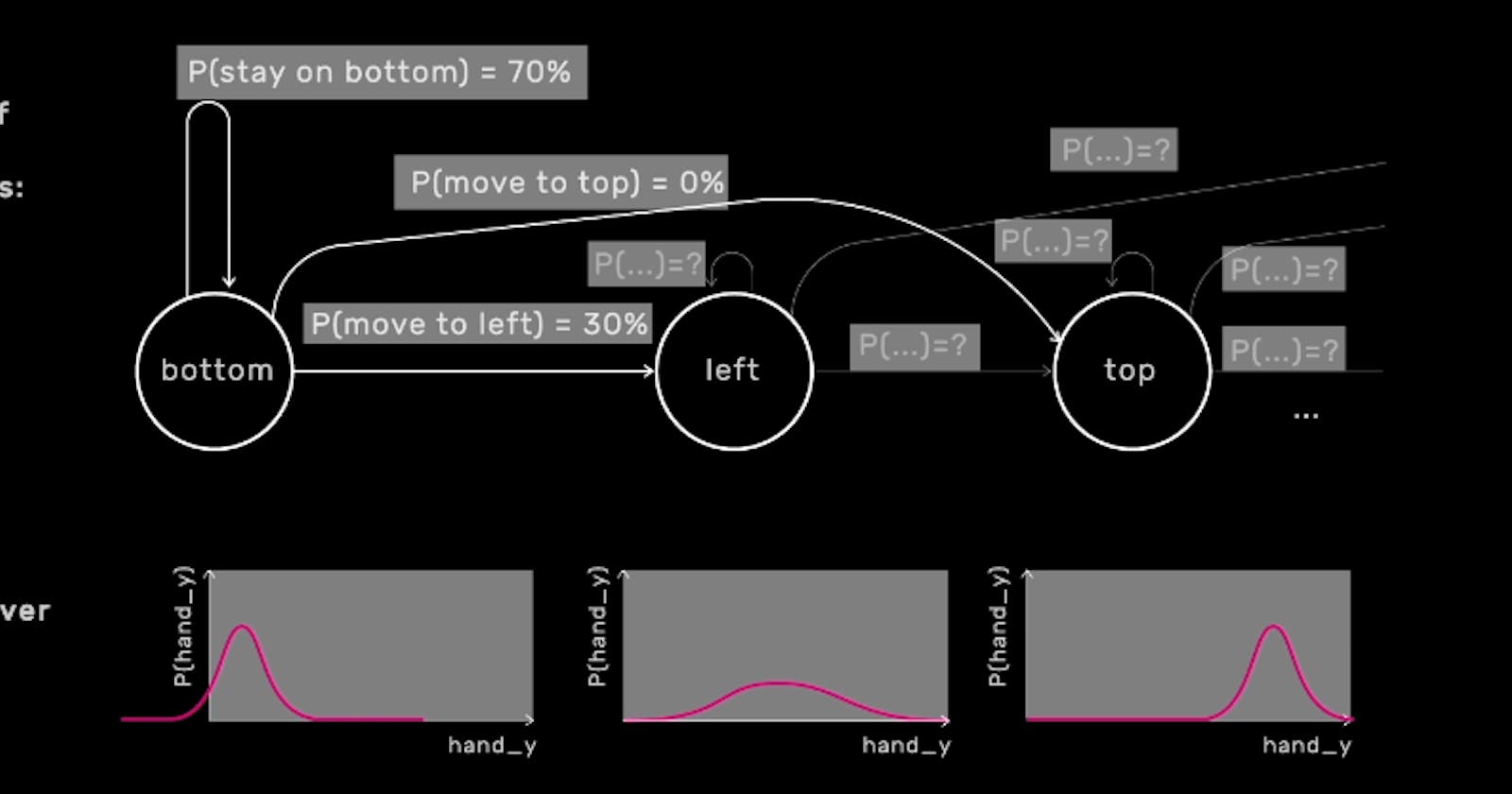
One of the biggest challenges in creating a good HMM is to set all of the parameters of the probability distributions. Like in Naive Bayes, it’s the training process that sets these probabilities from the data, hopefully in a reasonable way. But with so many parameters that need to be set, Hidden Markov Models can require a very large amount of data to be trained well.
](https://cdn-images-1.medium.com/max/2000/1*21e6wPgM9xSKThc-jsdvpA.png)
In general, HMMs won’t do well at all if we try to train them on just one example per class, whereas, dynamic time-warping, as we saw can do great, often with just one example. Even if we have several dozens of examples or even several hundred examples per class, we might still find that HMMs don’t build good models from the data.
So, if we’re working on a modelling problem where we have access to a very large data set, we might want to give HMMs a try. Otherwise, we may find that dynamic time-warping works better for us. Alternatively, we may want to explore some of the domain-specific algorithms for temporal modelling that are able to combine some of the benefits of both HMMs and dynamic time-warping by making additional assumptions about the learning problem, or the data.
That’s all for day 060. I hope you found this informative. Thank you for taking time out of your schedule and allowing me to be your guide on this journey. And until next time, be legendary.
Reference