



Recap From Day 057
Day 057, we looked at working with time; dynamic time warping for music and speech analysis. We learned that dynamic time warping doesn’t require us to do explicit segmentation. whereas using a classifier means we need to make a choice about when a gesture begins and ends in order to pass the classifier of feature vector representing the gesture from beginning to end.
Today, we will start looking at Hidden Markov Models(HMMs).
Working with time
Hidden Markov Models(HMMs)
Hidden Markov Models, or HMMs, are one of the most common approaches for modelling data over time in many domains. We’ve looked at it in depth before.
In dynamic time warping, we directly compared the current sequence to each of the sequences in our training set. This looks a lot like k-nearest-neighbour classifiers where we make decisions on new data only by considering the training examples directly.
](https://cdn-images-1.medium.com/max/2000/1*rGishvLC-Fo30UomnF8-HA.png)
Contrast this to the other classifiers we discussed which use the training examples to explicitly build some model of the data. For instance, the decision stump classifier employs a model which is simply a line drawn through the feature space, or a hyperplane if we’re working in higher dimensions. It uses the training data to find the best position for this line.
](https://cdn-images-1.medium.com/max/2000/1*suhFi11jUiToNLtKxGaUjQ.png)
Or consider the Naive Bayes classifier which uses the training data to estimate the parameters of a few simple probability distributions.
HMMs employs several principles that are similar to Naive Bayes. Using our training data, we’re going to fit the parameters of several probability distributions that altogether describe our training data. Except, in this case, these distributions will also describe how our data is likely to change over time.
Specifically, a Hidden Markov Model models a gesture as a sequence of states. These states aren’t necessarily literal properties of the world, but they’re related to properties of the world that we can measure.
](https://cdn-images-1.medium.com/max/2000/1*S-jQ_rHaFzHgeFOqYMudxg.png)
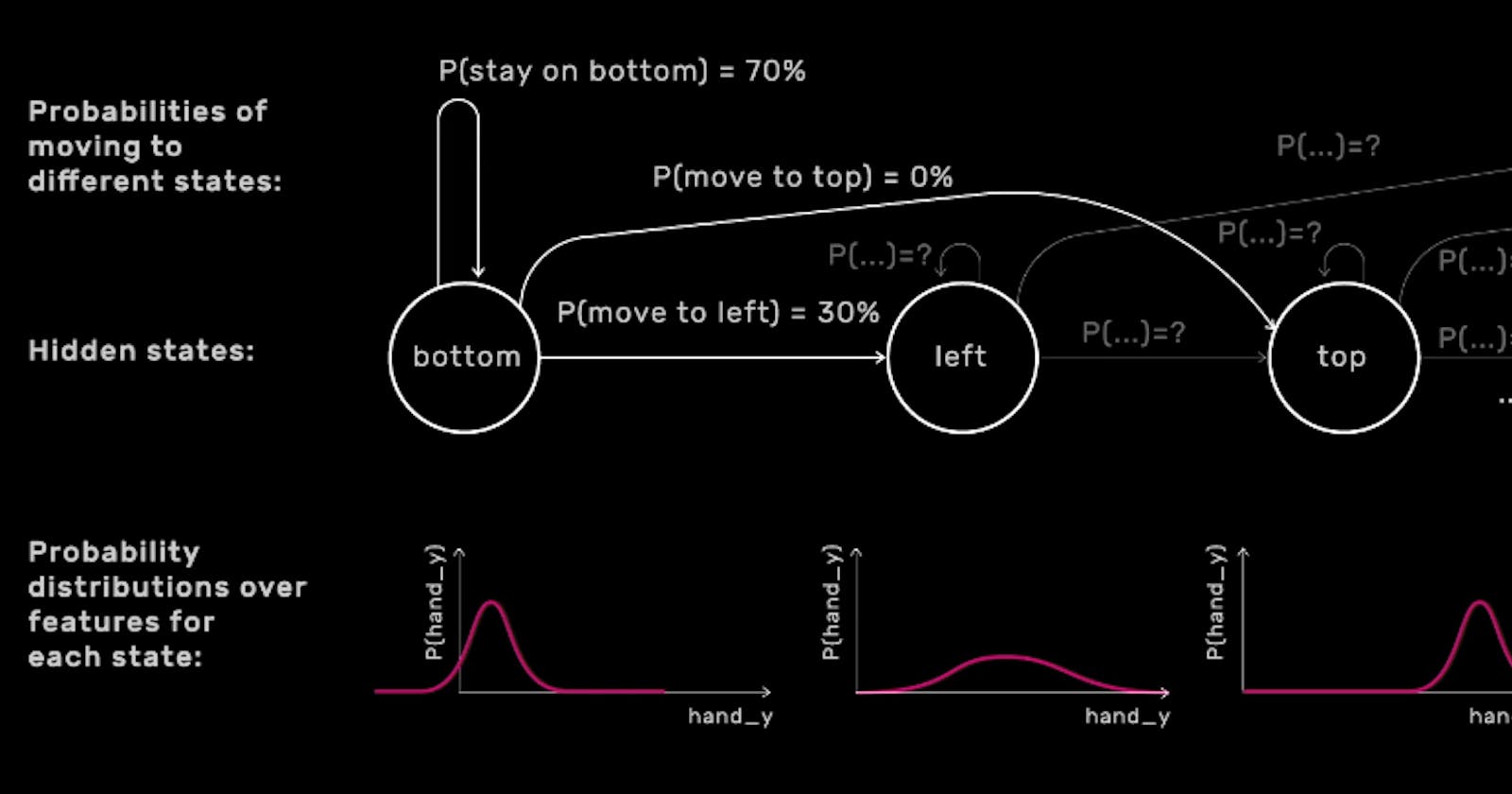
For example, let’s say we’re drawing a circle in the air. In English, we might say that we start at the bottom of the circle, then move to the left, to the top, to the right, and back to the bottom. We could model this gesture using an HMM with four hidden states: bottom, left, top, right.
We can also say that when we draw a circle we move in sequence from bottom, to left, to top, to right, in that order. To be more precise, it might also be appropriate to say that we could exist in one of these states for a while before moving on to the next one.
Let’s look at how this relates to the more general formulation of a Hidden Markov Model. In general, our Hidden Markov Model have some number of hidden states. In each state, we have a probability distribution over the feature values we’re most likely to see if the gesture is currently in that state.
](https://cdn-images-1.medium.com/max/2000/1*S_LqhS1X14_a91oaRPFN6A.png)
This distribution is likely to be quite different from one state to the next. For instance, it’ll be different at the bottom of the circle from at the top. Each state also has a probability associated with moving to any other state or staying in the same state.
](https://cdn-images-1.medium.com/max/2000/1*ZRCpykX-n0U6nd2DGj9eoQ.png)
So, training a Hidden Markov Model involves using the training data to set these probabilities. The probability distribution over the feature measurements that we might observe in each hidden state as shown by the highlighted areas in the image below,
](https://cdn-images-1.medium.com/max/2000/1*VO6fulry8JNPOdBt22UcuA.png)
and the distribution describing the ways that one hidden state can move into another hidden state as shown by the highlighted areas in the image below.
](https://cdn-images-1.medium.com/max/2000/1*qLRSMQryGmhiO9fJYZN1iw.png)
Once an HMM is trained, we can ask the following questions: given a sequence of data that we’ve just observed, how likely is this sequence to be generated from that specific HMM? If we have two HMM trained, say one for a circle gesture and one for a triangle gesture, this allows us to use HMMs for classification.
That’s all for day 058. I hope you found this informative. Thank you for taking time out of your schedule and allowing me to be your guide on this journey. And until next time, be legendary.
Reference