




Recap from Day 016
In day 016 we looked into Unsupervised Learning and how clustering works. We learned that *“Unsupervised learning is a type of machine learning algorithm used to draw inferences from datasets consisting of input data without labeled responses”*
Lets get started with today’s content.
Unsupervised Learning Techniques
As we saw in day 016, most unsupervised learning techniques are a form of cluster analysis.
“Cluster analysis or clustering is the task of grouping a set of objects in such a way that objects in the same group (called a cluster) are more similar (in some sense) to each other than to those in other groups (clusters).”
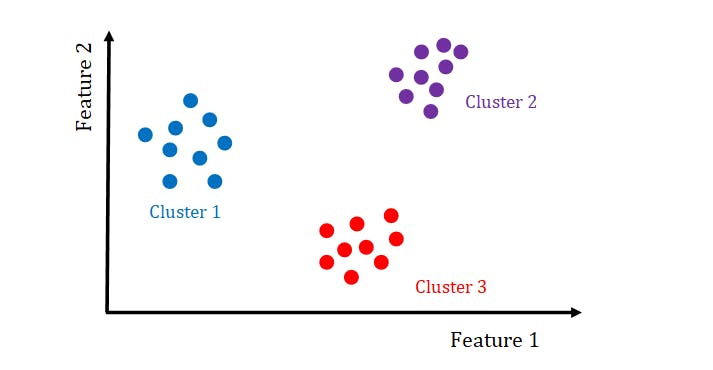 Clusters
Clusters
Cluster analysis itself is not one specific algorithm, but the general task to be solved. It can be achieved by various algorithms that differ significantly in their understanding of what constitutes a cluster and how to efficiently find them.
Clustering can be roughly distinguished as:
Hard clustering, where each data point belongs to only one cluster
Soft clustering, where each data point can belong to more than one cluster
You can use hard or soft clustering techniques if you already know the possible data groupings.
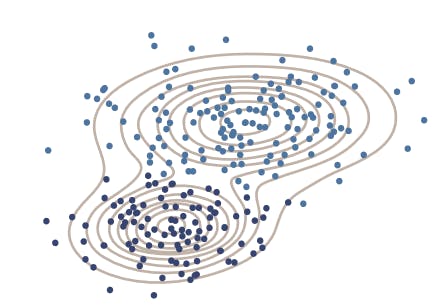 Gaussian mixture model used to separate data into two clusters
Gaussian mixture model used to separate data into two clusters
If you don’t yet know how the data might be grouped:
Use self-organizing feature maps or hierarchical clustering to look for possible structures in the data.
Use cluster evaluation to look for the “best” number of groups for a given clustering algorithm.
Great Job. You made it to the end of day 017. I hope you found this informative. Thank you for taking time out of your schedule and allowing me to be your guide on this journey.
Reference
MathWorks- 90221_80827v00_machine_learning_section4_ebook_v03 pdf