




Recap from Day 015
In day 015 we learned about Improving Models and we saw that “Improving a model means increasing its accuracy and predictive power and preventing overfitting (when the model cannot distinguish between data and noise). Model improvement involves feature engineering (feature selection and transformation) and hyperparameter tuning.”
Wow! it’s 16 days already. Are you still here? Yeah. I’m still here, and I hope to be till day 100 and beyond.
Unsupervised Learning
We’ve been exploring supervised learning for some days now. Today, we’ll start looking at unsupervised learning.
“Unsupervised learning is a type of machine learning algorithm used to draw inferences from datasets consisting of input data without labeled responses. The most common unsupervised learning method is cluster analysis, which is used for exploratory data analysis to find hidden patterns or grouping in data.”
When you want to explore your data but don’t yet have a specific goal or are not sure what information the data contains, unsupervised learning is the solution. It’s also a good way to reduce the dimensions of your data.
“As a musician, you could train an unsupervised learning algorithm on melodies you’ve written and, perhaps, discover that you tend to have three or four different types of melodic structure that you use over and over again.”
Cluster analysis, which is used for exploratory data analysis to find hidden patterns or grouping in data, is the most common unsupervised learning method used.
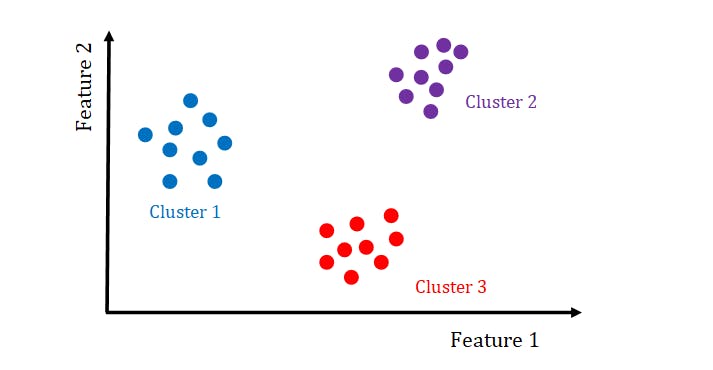 Clustering
Clustering
As a musician, “you can look for patterns in works by hundreds or thousands of other artists or composers and use this to discover similarities in patterns in a bottom up way, defined by whatever type of features you choose rather than describing their work in terms of culturally defined top down categories for describing genre or style.”
“Unsupervised clustering can also be used for building new interfaces for interaction.”
Let’s say you are an electronic musician and you have thousands of audio samples or loops stored on your computer and you want to look for new samples to use. Instead of searching for a sample by typing in a search keyword like “groovy” or navigating a complicated directory structure by clicking through a bunch of folders until you reach the synth effects you want to use. An alternative is to extract features like spectra centroid or RMS, and maybe statistics like average or standard deviation describing how these features change over the course of an audio file. You could then run a clustering algorithm to detect clusters of samples that are likely to sound similar and then you could visualize and browse your sample collections based on these perceptually relevant clusters rather on the sounds files names or the way they were packed into a directory by the sample library vendor.
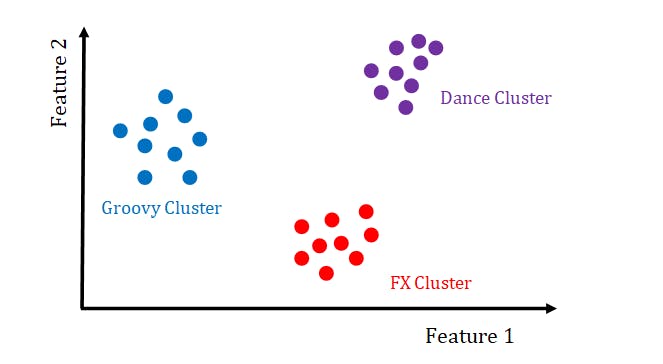 Clustering
Clustering
Unsupervised learning can even be used to come up with new features(We’ll learn about that tomorrow).
Great Job. You made it to the end of day 016. I hope you found this informative. Thank you for taking time out of your schedule and allowing me to be your guide on this journey.
Reference
MathWorks- 90221_80827v00_machine_learning_section4_ebook_v03 pdf
*https://www.mathworks.com/discovery/unsupervised-learning.html*