




Recap from Day 014
In day 014 we continued with Common Regression Algorithms, touching Regression Tree and Generalized Linear Model.
Today, we’ll look at Improving Models.
Improving Models
Enhancing a model performance can be challenging at times. It often involves iterating through some process and trying out a few variations .
“Improving a model means increasing its accuracy and predictive power and preventing overfitting (when the model cannot distinguish between data and noise). Model improvement involves feature engineering (feature selection and transformation) and hyperparameter tuning.”
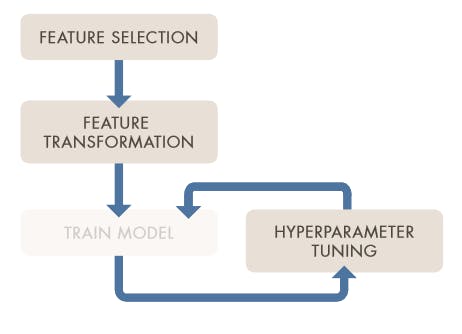 Source: MathWorks- 90221_80827v00_machine_learning_section4_ebook_v03 pdf
Source: MathWorks- 90221_80827v00_machine_learning_section4_ebook_v03 pdf
Feature Selection
Feature selection is the process of selecting a subset of relevant features) (variables, predictors) for use in model construction. Identifying the most relevant features, or variables, that provide the best predictive power in modeling your data. This could mean adding variables to the model or removing variables that do not improve model performance.
The goal of feature selection is to come up with the smallest set of features that best captures the characteristics of the problem being addressed. The smaller the number of features used, the simpler the analysis will be. But of course, the set of features used must include all features relevant to the problem.
Feature Transformation
Feature transformation involves mapping a set of values for the feature to a new set of values to make the representation of the data more suitable or easier to process.
“Turning existing features into new features using techniques such as principal component analysis, nonnegative matrix factorization, and factor analysis. Feature transformation is a form of dimensionality reduction. The three most commonly used dimensionality reduction techniques are:”
Principal component analysis (PCA)
Nonnegative matrix factorization
Factor analysis
Hyperparameter Tuning
“The process of identifying the set of parameters that provides the best model. Hyperparameters control how a machine learning algorithm fits the model to the data.”
“Like many machine learning tasks, parameter tuning is an iterative process. You begin by setting parameters based on a “best guess” of the outcome. Your goal is to find the “best possible” values — those that yield the best model. As you adjust parameters and model performance begins to improve, you see which parameter settings are effective and which still require tuning”
Three common parameter tuning methods are:
Bayesian optimization
Grid search
Gradient-based optimization
You made it to the end of day 015. I hope you found this informative. Thank you for taking time out of your schedule and allowing me to be your guide on this journey.
Reference
MathWorks- 90221_80827v00_machine_learning_section4_ebook_v03 pdf