




Recap from Day 010
In day 010 we continued with some common classification algorithms(Bagged & Boosted Decision Trees Discriminant Analysis)
Today, we’ll explore support Vector Machines(SVM) on a deeper level.
Support Vector Machines(SVM)
Some days ago, we learned that given a set of training examples, each marked as belonging to one or the other of two categories, an SVM training algorithm builds a model that assigns new examples to one category or the other.
We also learned that “SVM classifies data by finding the linear decision boundary (separating line) between data of two classes.
 SVM
SVM
Looking at the image below, there are three lines. Which line do you think separates the data?
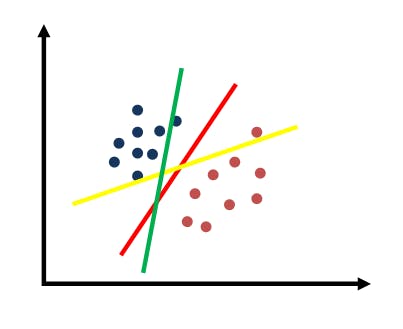 SVM: Separating Line
SVM: Separating Line
Fantastic intuition. The red line is the one that separates the data. Let’s look at another one. Think of the line that best separates the data.
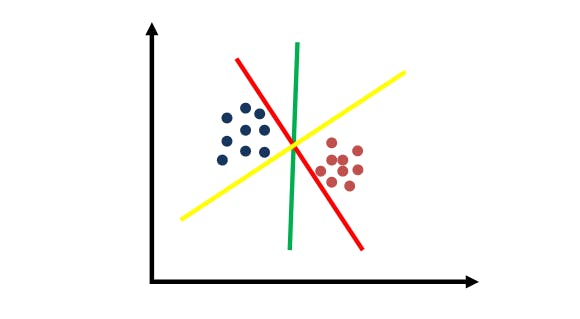 SVM: Choosing Between Separating Lines
SVM: Choosing Between Separating Lines
Awesome intuition. All three of them seems to separate the data. But the green line is the best separator. Why is this so? the best separator maximizes the distance to the nearest data point, and it’s relative to both classes, as shown below.
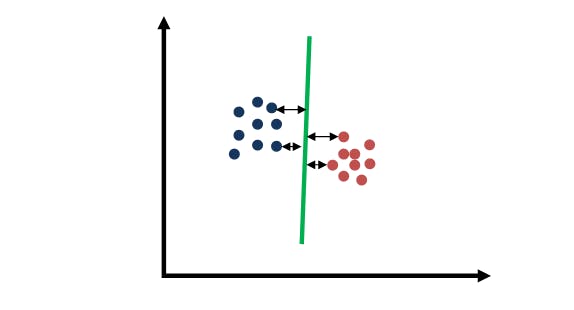 SVM: What makes a good separating line
SVM: What makes a good separating line
That distance is often called margin. Let me show you three linear separators for the same dataset. Which one do you think maximizes the margin?
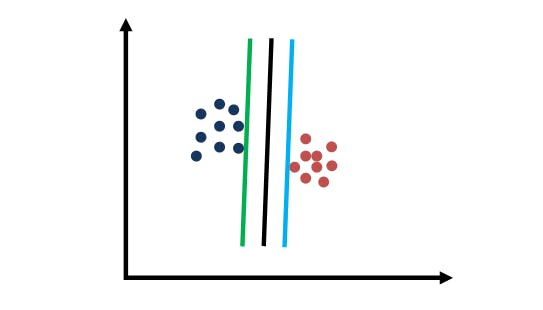 SVM: Practice with margins
SVM: Practice with margins
The best separator is the black line. The reason why we picked it is because it seems to be most robust to classification errors. For instance, if we pick the green or the light blue line, a small amount of noise will make the label flip.
The inside of Support Vector Machine is to maximize the robustness of our result.

SVMs And Tricky Data Distributions.
Let’s look at SVMs and tricky data distributions. Using the image below, which of the two lines do you think maximizes the data and will be the correct result of a Support Vector Machine?
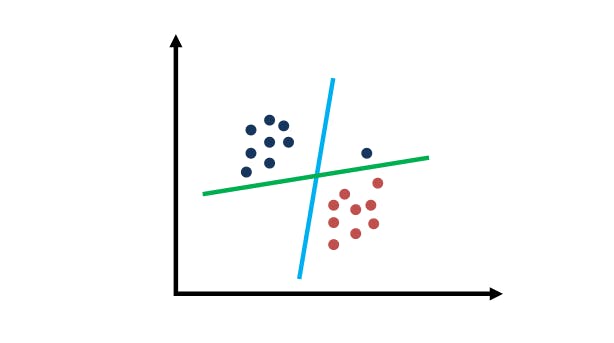 SVM: Tricky Data Distribution
SVM: Tricky Data Distribution
The green line is the one that maximizes the margin of this tricky data distribution. The light blue line does maximize the margin in some sense to all the data points, but it makes a classification error. The blue circle is on the wrong side of the light blue line. But with the green line, all the points are classified correctly.
SVM puts first and foremost the correct classification of the labels and then maximize the margin. For SVM, we are trying to classify correctly and subject to that constraints, we maximize the margin.
Trending AI Articles:
1. Deep Learning Book Notes, Chapter 1
2. Deep Learning Book Notes, Chapter 2
3. Machines Demonstrate Self-Awareness
4. A Crypto that will Pay You
SVM Responses To Outliers.
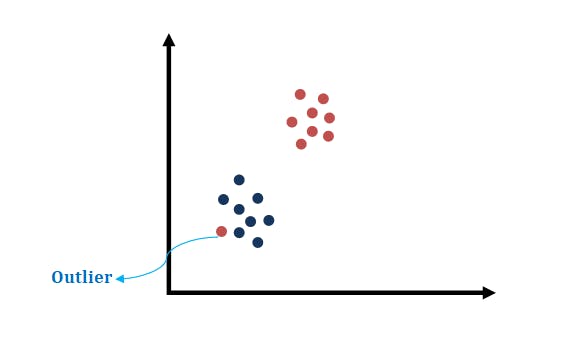 SVM Responses To Outliers.
SVM Responses To Outliers.
Sometimes for SVM, it seems impossible to do the right job. A typical example is shown in the data set above, where clearly, no decision surface exist that would separate the two classes. In such case as shown in the example above, instead of just giving up, SVMs will make a decision boundary such as the one shown below.
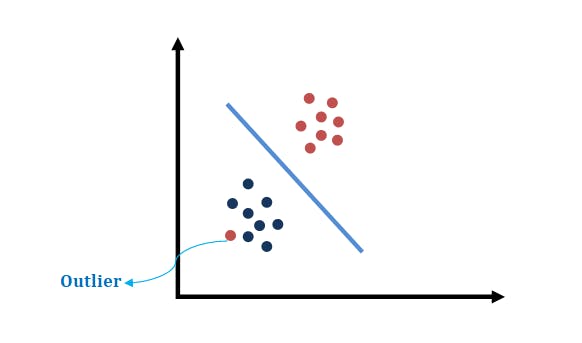 SVM Responses To Outliers.
SVM Responses To Outliers.
SVMs are good at making the type of decision boundary above. They often find the decision boundary that maximizes the clearance to both data sets and tolerate at the same time individual outliers as shown above.
In this final example below, there seems to be an outlier. Say we are willing to ignore an outlier, which separating line would you pick?
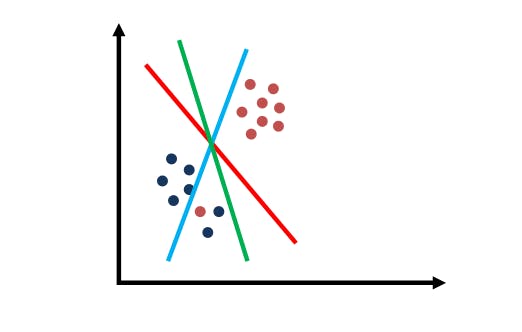 SVM: Outlier Example
SVM: Outlier Example
Excellent. It’s the red line because it’s the one that truly maximizes the margins to those points, ignoring the outlier.
In conclusion, VM is somewhat actually robust to outliers and it somehow mediates the attempt to find the maximum margin separator and the ability to ignore outlier as a trade-off.
Wow! You made it to the end of day 011. I hope you found this informative. Thank you for taking time out of your schedule and allowing me to be your guide on this journey.


