




Recap from Day 010
In day 009, we briefly looked at features and labels. Today, we’ll continue with common classification algorithms.
Common Classification Algorithms
Bagged and Boosted Decision Trees
In this section, you’ll learn about Bagged and Boosted Decision Trees as seen in MathWorks’s machine learning pdf section 4.
In these ensemble methods, several “weaker” decision trees are combined into a “stronger” ensemble. A bagged decision tree consists of trees that are trained independently on data that is bootstrapped from the input data Boosting involves creating a strong learner by iteratively adding “weak” learners and adjusting the weight of each weak learner to focus on misclassified examples.
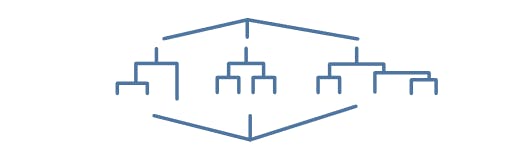 Source: MathWorks — Bagged and Boosted Decision Trees
Source: MathWorks — Bagged and Boosted Decision Trees
Best Used…
When predictors are categorical (discrete) or behave nonlinearly
When the time taken to train a model is less of a concern
Discriminant Analysis
“Discriminant analysis builds a predictive model for group membership. The model is composed of a discriminant function (or, for more than two groups, a set of discriminant functions) based on linear combinations of the predictor variables that provide the best discrimination between the groups.” “The functions are generated from a sample of cases for which group membership is known; the functions can then be applied to new cases that have measurements for the predictor variables but have unknown group membership.”
 Source: MathWorks — Discriminant Analysis
Source: MathWorks — Discriminant Analysis
Best Used…
When you need a simple model that is easy to interpret
When memory usage during training is a concern
When you need a model that is fast to predict
You made it to the end of day 010. Thank you for taking time out of your schedule and allowing me to be your guide on this journey.
Refrence: Mathworks- 90221_80827v00_machine_learning_section4_ebook_v03.pdf
*https://www.ibm.com/support/knowledgecenter/en/SSLVMB_23.0.0/spss/base/idh_disc.html*