




Recap from Day 008
In day 008, we continued with the common classification algorithms, by looking at Neural Network and Decision Tree.
Today, we’ll briefly look at features and labels before we continue with our common classification algorithms tomorrow.
Features
In machine learning, we often take as input features and we try to produce labels.
A feature is an individual measurable property or characteristic of a phenomenon being observed. — wikipedia)
Let’s take, for instance, we have a piece of music, and we want to classify the music as either calm and not calm. What we’ll do is, we’ll extract measurable properties(features) from the music. This might be things such as tempo, or intensity of the song or things like genre, or gender of the voice.
In speech recognition, features for recognizing phonemes can include noise ratios, length of sounds, relative power, filter matches and many others.
Extracting or selecting features is a combination of art and science; developing systems to do so is known as feature engineering. It requires the experimentation of multiple possibilities and the combination of automated techniques with the intuition and knowledge of the domain expert.
Labels
Labels are outputs values to which an algorithm maps data points for the feature chosen to be the feature being predicted. So, if using our example above, Tempo is used as our feature, we’re trying to predict, the labels would be relaxed or fast.
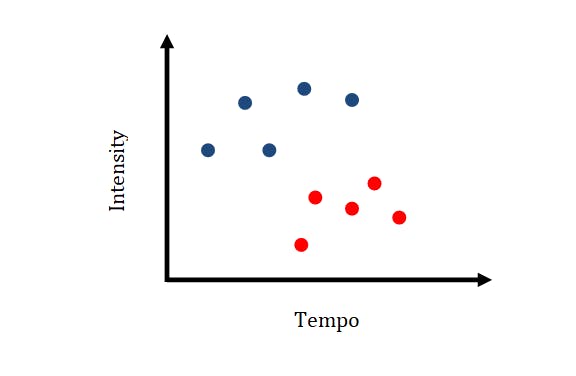 Features And Labels
Features And Labels
Labels can be obtained by asking humans to make judgments about a given piece of unlabeled data (e.g., “Does this photo contain a horse or a cow?”), and are significantly more expensive to obtain than the raw unlabeled data
You made it to the end of day 009. Thank you for taking time out of your schedule and allowing me to be your guide on this journey.