




100 Days Of ML Code — Day 005
Recap from Day 004
In day 004 we went through an overview of Wekinator and a walkthrough of Wekinator, linked from Wekinator’s website.
I’m sure you’re already imagining the numerous ways you’ll use machine learning in your work, having seen what Wekinator is capable of.
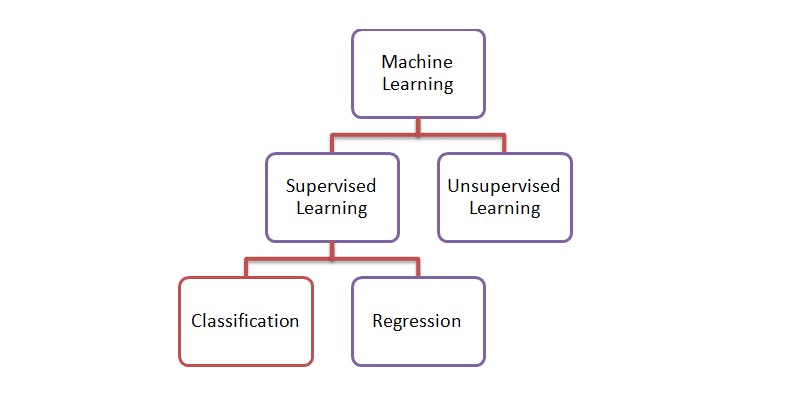
If you remember, when we looked at how machine learning works in day 002, we learned that Machine learning uses two types of techniques: supervised learning, which trains a model on known input and output data so that it can predict future outputs, and unsupervised learning, which finds hidden patterns or intrinsic structures in input data. Then we pitched our tent in supervised learning.
Today, we’re going to look at the techniques used by supervised learning for developing predictive models. These techniques are classification and regression.
Classification
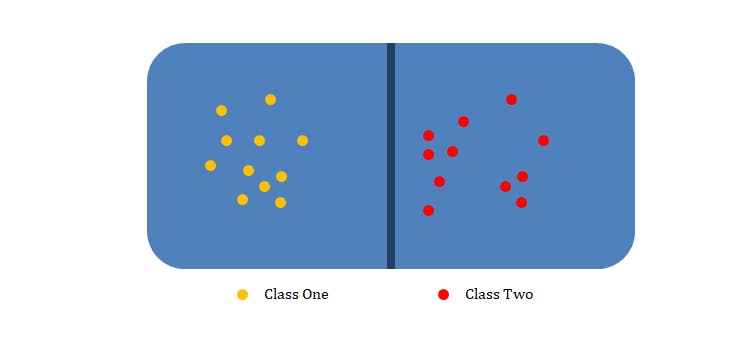
Classification models classify input data into categories. In other words; classification is the problem of assigning a label or a category to any incoming input.
 Classification
Classification
The specific number of categories that you’re teaching the computer to recognize when you build a classifier is also called classes. These classes could be, am I making the Doh Solfège hand sign, versus the Lah Solfège hand sign, versus the Ray Solfège hand sign as in seen in our interactive system scenario. Or if you’re building a sound classifier, you might want it to label an MP3 file as being Jazz music, Rock music, R n B Music, Afro Music or Speech.
“When you are doing straightforward classification, you should be thinking about these categories in a very simple way. You can assume they are mutually exclusive. That is, a piece of music can’t be both Rock and Classical and it can’t be somewhere in between.” — Dr. Rebecca Fiebrink
Typically, you can assume that if you train a classifier to recognize three (3) categories, it’s always going to produce a label that is one of those three (3) categories and nothing else.
 Classification
Classification
Whenever you train a classifier, if you find out that you’re not happy with what it’s doing, you can change your training examples to make it do something different. Note that Using larger training datasets often yield models that generalize well for new data
You may be asking, how does a supervised learning algorithm build classifiers from training examples? The answer is, it uses classification algorithms. If your input can be separated into specific groups or classes, use classification algorithms.
Wow, you made it to the end of day 005. Tomorrow, we’ll take a closer look at the most commonly used classification algorithms.
Thank you for taking time out of your schedule and allowing me to be your guide on this journey.